
Taking CosmosDB and pushing to Neo4j
TL; DR.The project reads data from a CosmosDB instance, and inserts it into Neo4j – there’s no clever ‘re-modeling’ – just a simple push in. Have a look at the project site for more info!…
TL; DR.The project reads data from a CosmosDB instance, and inserts it into Neo4j – there’s no clever ‘re-modeling’ – just a simple push in. Have a look at the project site for more info!…
Neo4j has a few projects Arrows, Neo4j Data Importer which can export to JSON file, which is handy for passing around. But once you’ve designed your model, you move on to the development side of…

TL;DR; – It’s on GitHub: https://github.com/cskardon/Neo4jDriverWithAzureFunctionsDI You, just now I know what you’re thinking, that is an exciting headline, and you’re right! Back in May… May 2018 (!!!) I wrote a blog post about using…
The oldest bug (and indeed first) for the Power BI Connector for Neo4j is about how you can’t do an Auto-Refresh on the server side of Power BI. I’ve tried many things, but, it’s taken…

I’ve recently spent some time getting Intra-cluster encryption up and running on a Neo4j Causal Cluster, both with Self-Signed certificates, and proper ones. Largely, due to the way SSL works, in particular with respect to…

I know most of you will be here for the EPIC title picture, the dinosaurs are from http://deviantart.com/susannehs/ – I hope she isn’t too disappointed 😮 The other art, well, that’s all mine… if you…

One of the things which puts people off of Windows (and this likely won’t solve it, but hey!) is that it’s seen as BLOATWARE. Needing lots of RAM just to start up. Largely, that’s due…

Neo4j’s cluster setup is great for ease of understanding and use, but it had one weakness that affected a particular use case. The use case is the user who wants the High Availability (HA) of…

In my previous post we showed how we could test a few different areas of the Neo4j.Driver nuget package. One area we didn’t touch was the SessionConfig – as part of the IAsyncSession. Now, for…
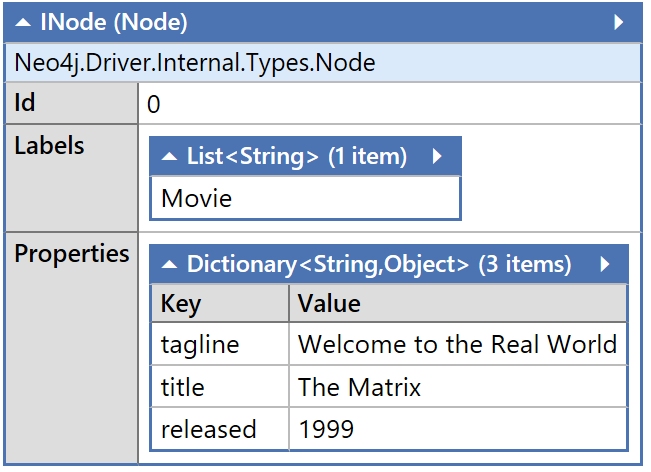
There are a few challenges when dealing with the official Neo4j.Driver when it comes to testing, over a period of time, I’ve hit a few of them, and thought it would be good to share…